Diseñando una arquitectura Big Data para la ingesta de datos de BICIMAD

El objetivo inicial de este post es diseñar una arquitectura de ingesta de datos en tiempo real y batch sobre el api pública de BICIMAD con tecnología OpenSource. En siguientes post construiremos la arquitectura propuesta y explicaré paso a paso el proceso llevado a cabo.
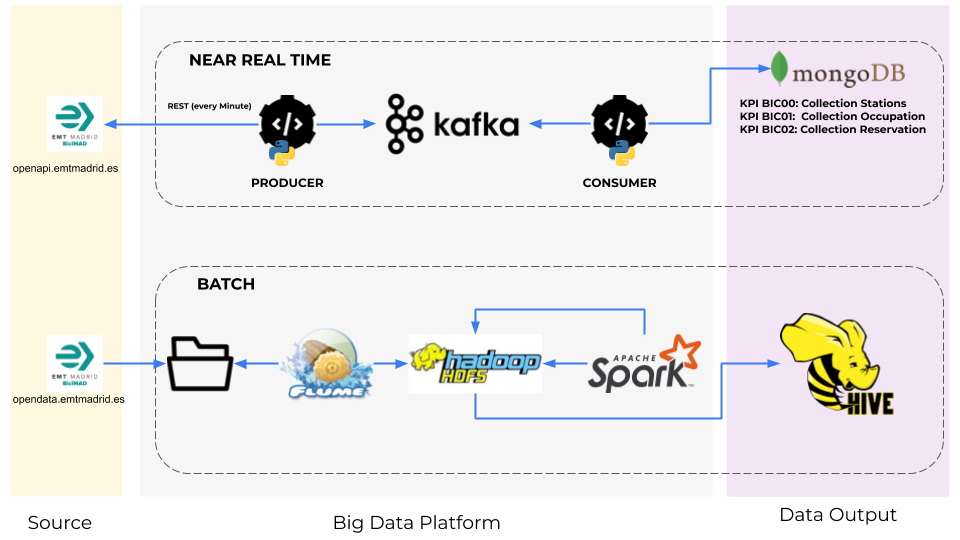
Como podemos ver, nos encontramos ante una arquitectura lambda con un layer en near real time y otro en batch.
Comenzaremos detallando el funcionamiento de la capa superior. En primer lugar, mencionar que la he definido como near real time por la periodicidad en la que el producer solicita información al api de BICIMAD y la propaga al bus de kafka. Para llevar a cabo esta práctica, he definido una periodicidad de un minuto. No obstante, es un parámetro configurable como detallaré posteriormente en siguientes post.
En esta petición que hacemos desde el producer al api de BICIMAD, obtenemos el estado de todas las estaciones en tiempo real y lo volcamos al bus de kafka en un único mensaje a través del topic stations-topic. La clave es el timeStamp de la petición y el valor el JSON obtenido.
El mensaje viaja hasta el consumer a través de los brokers definidos. En este caso, al igual que el producer anterior, el consumer está desarrollado en python y permite escuchar el topic stations-topic y obtener el mensaje con el contenido del JSON y el timestamp. Una vez obtenido el mensaje, procesa la información obteniendo los siguientes KPIS:
KPI BIC00: Estado de todas las estaciones en tiempo real : A través de este KPI podemos saber el estado de todas las estaciones de BICIMAD en tiempo real.
KPI BIC01: Ocupación en tiempo real : A través de este KPI podemos medir el nivel de ocupación en tiempo real de todas las estaciones de BiciMAD. Extraemos la información directamente del número total de bases y las bases ocupadas.
KPI BIC02: Reservas en tiempo real: Al igual que el punto anterior, para el equipo de negocio de BiciMAD, tener el número de reservas en tiempo real de todas las estaciones, les permite predecir el comportamiento por horas y mejorar el servicio en ciertos horarios pico.
Los kpis son almacenados en 3 colecciones de mongoDB (una por kpi) donde posteriormente pueden ser explotados a través de una query en mongo u otro servicio de visualización de datos. He optado por tener tres colecciones diferenciadas por si queremos optimizar y añadir nuevas funcionalidades a cada uno de los kpis en el futuro. Podríamos haber guardado los tres kpis en una única colección si fuera necesario.
Por otro lado, nos encontramos con la capa de procesamiento en batch. Para la ingesta de información he optado por utilizar Apache Flume.
Con apache Flume podremos ingestar el fichero JSON mediante la funcionalidad spooldir e insertar esta información en el layer raw de HDFS. Para ello, hemos configurado el agente, la fuente de origen, el canal y donde se va a volcar la información (sink) como mencionaremos en el apartado de Script & Code.

Una vez ingestados los datos y volcados en HDFS, utilizaremos Apache Spark para procesarlos.
Apache Spark es un Framework Open Source que nos permite procesar la información del JSON de origen y obtener los parámetros del JSON que nos interesan analizar posteriormente.
La información procesada por Apache Spark, se vuelca de nuevo en HDFS para su posterior explotación con Apache Hive. Apache Hive es una infraestructura de almacenamiento de datos construida sobre Apache Hadoop que nos proporciona una capa de consulta, análisis de datos y agregación sobre la misma.
Por otro lado, otra de las ventajas de Apache Hive es que nos permite realizar consultas SQL sobre HiveQL, minimizando el esfuerzo para poder obtener y representar los KPIS preprocesados hasta el momento.
En los siguientes post, explicaremos como construir ambos layers y los resultados obtenidos tras la implementación y test.
Felicidades estimado Carlo, buen trabajo. Una consulta ya publicaste la segunda parte del presente trabajo?, es decir como construir ambos layers y los resultados obtenidos tras la implementación y test.