Big Data: El journey del dato

Nos remontamos hasta los años 80. En pleno desarrollo de lo que hoy conocemos como Internet, I.A Tjomsland en su charla, “Where Do We Go From Here?” hacía una analogía a la Primera Ley de Parkinson sobre el valor del dato para la industria y la toma de decisiones : “ Los datos se expanden hasta llenar el espacio disponible para el almacenamiento”. Dejaría entrever cuál sería la tendencia de crecimiento exponencial del dato en los próximos años y la oportunidad de generar valor a partir de dicha información.
Años más tarde y con la expansión de World Wide Web, se empiezan a generar de forma masiva millones de datos relativos a la distribución de información. Al mismo tiempo, se empiezan a generar millones de datos relacionados con el primer informe de Base de Datos de windows, que adoptaron de forma masiva diferentes empresas mundiales aportando lo que hoy conocemos como inteligencia de negocio.
En este nuevo paradigma empresarial y con la expansión de internet en Estados Unidos, algunos ya empezaron a mencionar el gran problema que tendría el almacenamiento y la homogeneización de datos pero no es hasta 1997 cuando Michael Cox y David Ellsworth, trabajadores e investigadores de la NASA, crean el término que hacía analogía a este gran problema.
El término “Big Data” fue utilizado en un informe de la NASA donde exponían que “El aumento de los datos se estaba convirtiendo en un problema para los sistemas informáticos actuales”.
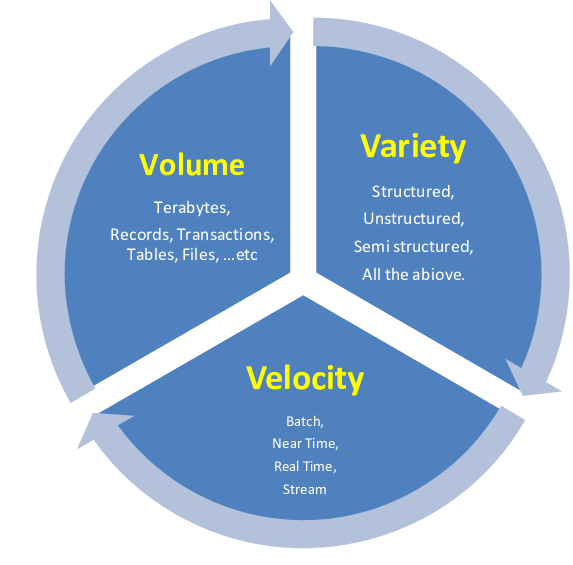
En los años siguientes, el crecimiento del dato tomó mayor relevancia en el sector empresarial y en las diferentes comunidades tecnólogas y científicas. Tanto es así, que en 2001 Doug Laney publicó un informe de investigación titulado “3D Data Management: Controlling Data Volume, Velocity, and Variety” Esto es lo que hoy conocemos como las 3vs del BIG Data.
Al mismo tiempo y por el auge de Internet, Google estaba trabajando en un sistema de indexación y almacenamiento para su motor de búsqueda con el que pudiera reducir el coste y mejorar la integridad de la información. En 2003 y 2004 comparte esta información con todo el mundo a través de dos papers: GFS (Google File System) y MapReduce. Pilares fundamentales que utilizará Doug Cutting para la creación y el lanzamiento de Hadoop en el año 2006.
Con la llegada de hadoop, Apache proporciona a todos los desarrolladores del mundo el framework open source que se convertiría en líder del ecosistema Big Data de las empresas y startups años más tarde.
Si tuviéramos que definir un punto de inflexión en el mundo Big Data, podríamos afirmar que es con este hito. A partir de este momento, millones de desarrolladores del mundo empezaron a crear soluciones de negocio sobre este framework. Hadoop, junto a la evolución y comercialización del cloud computing, iba cogiendo enteros como tecnología de computación distribuida, permitiendo tener soluciones de cómputo en tiempo real y batch para el tratamiento de información a empresas de diferentes sectores a un precio-oportunidad verdaderamente interesante.
Dos años más tarde, vería la luz uno de los productos tecnológicos más utilizados por las empresas. Hablamos de Cloudera.
Solución enterprise (principalmente) basada en hadoop que se consolida como la primera plataforma unificada para cantidades masivas de datos, proporcionando a la organización todas las soluciones de ingesta, procesamiento,almacenamiento y disponibilidad de la información.
Cloudera se convertía con ello en una de las referencias de mercado hasta el momento. No obstante, no tardó en llegar la competencia para repartir la tarta tan grande identificada en los diferentes sectores empresariales. En 2011 nace Hortonworks, alternativa open source a la plataforma cloudera. Plataforma unificada similar a Cloudera pero con un modelo open source, vendiendo servicios de soporte o consultoría frente al modelo de licenciamiento tradicional.
Ambas soluciones se fusionarán años más tarde (2019) para ocupar todo el mercado enterprise como solución única distribuida.
Al mismo tiempo del lanzamiento de Hortonworks nacen en el mercado internacional y europeo diferentes aplicaciones que revolucionarán años más tarde diferentes sectores. Entre ellas se encuentran Uber, Cabify, Netflix, Tinder, Instagram o Snapchat entre otras. Aplicaciones cuyo modelo de negocio gira entorno al dato y la contextualización de información para el usuario final basado en lo que hoy conocemos como location intelligence.
Así mismo, no podemos encasillar el uso de esta tecnología únicamente en el ámbito empresarial. Por ejemplo, Obama en 2012 fue el primer candidato en aprovechar dicha tecnología con la finalidad de obtener mejores resultados basándose en modelos predictivos.
Otros campos como la medicina, también comenzaron a aprovechar dicha tecnología para la explotación e identificación de patrones en diferentes enfermedades.
Por otro lado, si tuviéramos que decir cual es el segundo hito que impulsó esta tecnología, para mi sería el lanzamiento de Kubernetes.
Google lanza kubernetes en Junio de 2014 , producto que se convertiría en uno de los estándares de escalado y manejo de contenedores, facilitando con ello la creación de productos altamente escalables y distribuidos en la nube que junto al paradigma de microservicios lanzado unos años antes, se convertiría en una de las armas de distribución de diferentes servicios en la nube para computación de información y procesamientos de datos.
Meses después, Gartner en su informe anual Gartner Hype Cycle eliminaría la terminología Big Data del informe por su estabilidad en el mercado. Dejando con ello de ser una tecnología emergente en este momento y dando paso a otras como Machine Learning o AI .
Así mismo, 2015 se convierte en el año de la revolución iOT y las Smart Cities. El Mobile World Congress de Barcelona dejaba entrever la potencia del hardware y la expansión de la sensorización que empezaría a manifestarse a partir de este momento. El lanzamiento de la raspberry pi 2 marca un antes y un después en este campo. Hardware asequible con infinitas posibilidades de computación y comunicación. Pilares fundamentales en la ingesta de información y recopilación de datos que se apoyan en la computación en la nube y el Big Data para explorar modelos de negocio e información hasta ahora al alcance de muy pocos.
La expansión de estos sensores como vehículo para la ingesta de datos proporciona la creación de nuevos modelos de negocio que empezarían a emerger a partir del año 2016. Principalmente en el sector salud, donde la expansión de los wearables en el mercado doméstico, fue la pieza clave para la recopilación de información sobre nuestras constantes. Aunque también hablamos de modelos de car sharing como Bicimad, Zity, Wible o Jump de Uber.
Modelos de negocio que utilizan el Big Data como tecnología core para la explotación, donde la sensorización ha sido el medio de adquisición de información. La monetización del dato llevado al extremo gracias al estudio de patrones, el machine learning y la inteligencia artificial.
Frente a este crecimiento de nuevos modelos de negocio, velocidad y volumen de datos, el año 2017 se consolida como el año en el que la variedad es la punta de lanza que impulsa las inversiones y retornos en los proyectos Big Data. La mezcla de diferentes servicios y datos de proveedores para centrarse en el long tail de su negocio aportando un punto de vista diferente al nicho en el que deambulaban el flujo de datos de su compañía.
Soluciones como Smart Steps, Luca o BBVA Api Markets permiten a las empresas y startups mezclar diferentes puntos de vista basados en la localización, consumo o análisis sociodemográfico, aportando una visión a sus proyectos desde otra perspectiva. La conexión, procesado y mezcla de diferentes fuentes para crear y explorar nuevas experiencias y expectativas para sus clientes.
Además de la superposición de diferentes fuentes para análisis y explotación de mercados emergentes, las compañías se dan cuenta que los datos de las diferentes unidades de negocio son valiosos entre sí. No obstante, extraer esta información, en muchos casos, requiere de diferentes perfiles expertos y costosos.
Por ello, 2018 se convierte en el año en el que la inversión de tecnología dentro de muchas empresas se centra en la adquisición de herramientas de autoconsumo del dato, así como la generación de marketplaces dentro de la compañía para explotar y cruzar datos de sus clientes junto a las perspectivas de las diferentes unidades de negocio.
Gracias a soluciones como Alteryx, Trifacta o Paxata, la explotación y unificación del dato y la posterior explotación con herramientas como tableau o PowerBI, hacen del Big Data una tecnología cada vez más consolidada en las empresas del ámbito Europeo e internacional.
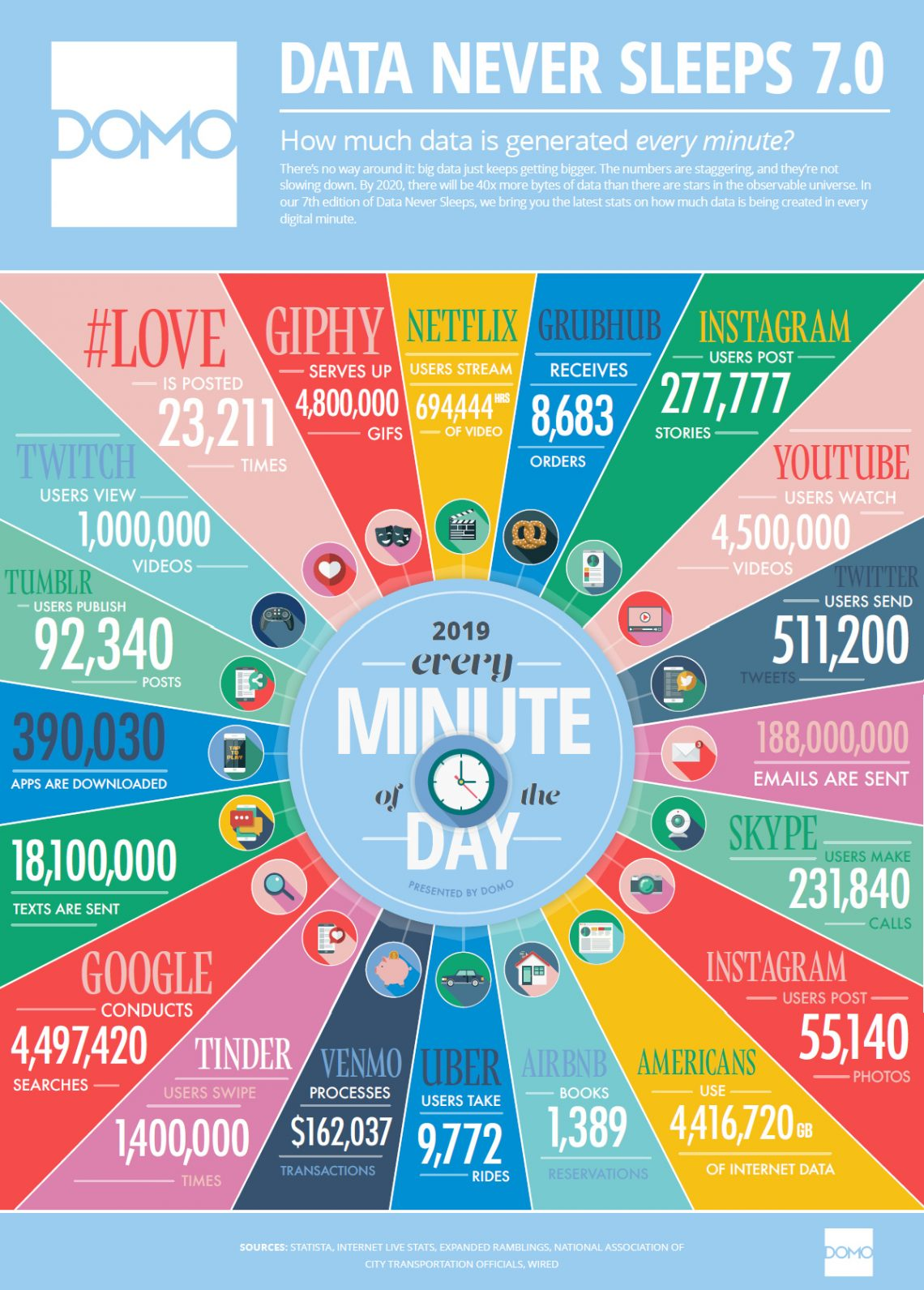
Al mismo tiempo que las empresas recopilan información de sus clientes, las procesan y generan valor de estos datos, la tecnología y las nuevas aplicaciones generan en el mercado nuevas demandas y volumen de información que hasta el momento no se habían generado.
Tal y como mencionaba Cisco en su informe anual de 2018 se prevé que el tráfico se multiplicará casi por tres desde 2013 hasta 2018. De 3,1 Zettabytes registrados en 2013 hasta 8,6 registrados en 2018.
Ante este volumen de información y generación de datos por el uso continuo de internet y los smartphones, podemos afirmar que el Big Data está evolucionando hasta el Huge Data.
Dicha expansión de información ha provocado un crecimiento a nivel de infraestructura tecnológica en las empresas españolas. Según el Instituto de Economía Digital de ESIC, el 35% de las empresas españolas han integrado esta tecnología dentro de sus empresas. Por lo tanto, podemos afirmar que diferentes verticales de negocio encuentran en el Big Data la solución a los diferentes retos actuales.
Análisis de abandono y predicción de la satisfacción en las Telco, gestión de riesgo y precios dinámicos en el sector seguros, predicción de la demanda y análisis del customer journey en el sector retail, prevención de fraude e impagos en el sector bancario o personalización y contextualización de contenidos en medios, son algunos de los proyectos y retos que están abordando las diferentes empresas nacionales e internacionales actualmente.
Por lo tanto, podemos concluir que el presente del Big Data es una realidad palpable en diferentes sectores. Se ha consolidado como el medio de crecimiento exponencial del negocio tradicional catalizando la información que generamos diariamente a partir de nuestra interacción con los medios digitales, aportando un valor diferencial que cambiará nuestro contexto económico y social en los próximos años.
Procesamiento del lenguaje natural, inteligencia artificial o aprendizaje automático serán los próximos pasos en esta nueva era del dato que unidos al control y el gobierno de la información, serán la clave de la anarquía o la oligarquía de los nuevos modelos de negocio y de la sociedad. ¿Estás preparado?